[ELK] 엘라스틱서치 데이터 노드를 효율적으로 관리하는 방법
안녕하세요. 황진성입니다.
지난 글에 이어서 데이터 노드를 효율적으로 관리/활용하는 방법에 대해 알아보겠습니다.
연산이 많고 접근이 잦은 데이터와 거의 접근되지 않는 데이터를 분리하면 비용, 공간 측면에서 크게 절약할 수 있습니다. 주로 대용량 데이터를 다루는 상황이라면 차이가 극명하게 날텐데, Elasticsearch에서는 어떻게 이 문제를 해결하는지 알아봅시다.
혹시 독자님도 JVM based 언어를 많이 사용하시는지 ~?
저는 이번 글을 쓰면서 JVM GC 힙 영역의 Survivor1 + Survivor2 + Eden + Old 구조가 떠올랐습니다. 접근 확률에 따라 점점 밀어넣는 방식인데, 그림을 대충 보시고 아래 글을 읽으면 이해가 조금 더 빠를 것 같습니다 😁
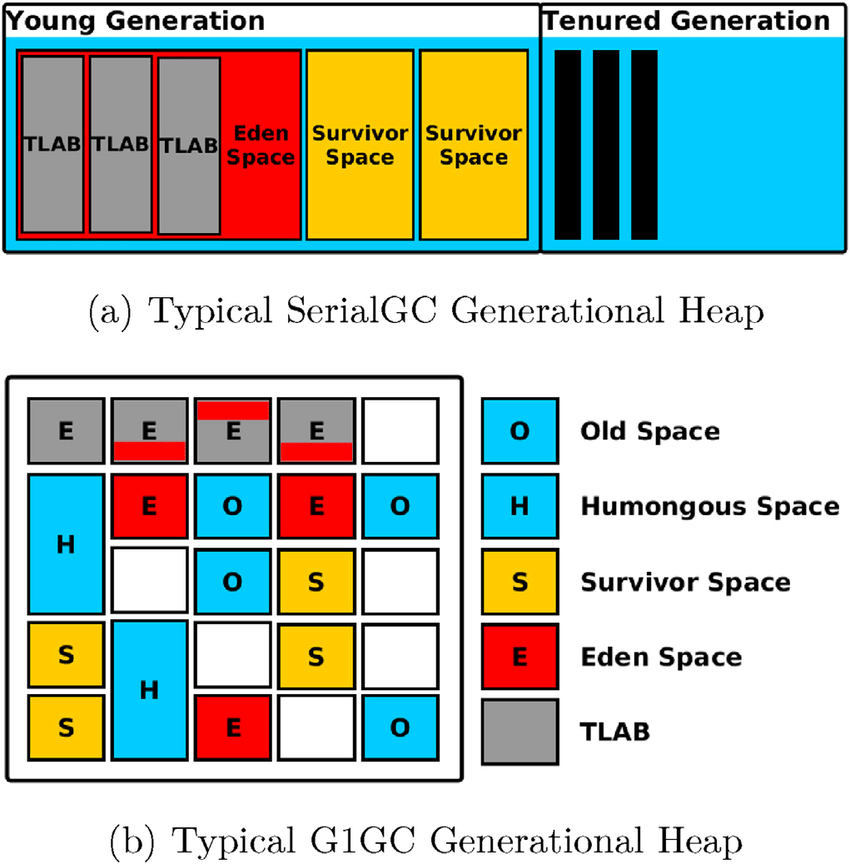
이 글의 내용은 작성일 기준 최신 버전인 Elasticsearch 8.10 문서를 따라 작성됐습니다.
핫/웜/콜드/프로즌 노드와 컨텐츠 노드
데이터 노드는 저장하는 데이터의 성격에 따라 핫(Hot), 웜(Warm), 콜드(Cold), 프로즌(Frozen), 컨텐츠(Content) 노드로 구분할 수 있습니다. 이렇게 노드를 구분하는 이유는 데이터 노드를 더 효율적으로 사용해 전반적인 클러스터 성능을 높이기 위함입니다.
핫 노드
node.roles = [ data_hot ] 핫 노드에는 활발하게 인덱싱과 검색이 일어나는 인덱스들을 위치시키고 충분한 리소스의 하드웨어를 할당해줘야 합니다. HDD보다는 SSD를 사용하는 것이 좋습니다. 회복탄력성을 위해 하나 이상의 레플리카를 사용하는 것을 권장합니다.
웜 노드
node.roles = [ data_warm ] 웜 노드에는 자주 사용하지 않는 데이터를 저장하는데, 쿼리의 빈도가 낮고 인덱싱은 일어나지 않는 인덱스들을 웜 노드에 저장합니다. 일반적으로 최근 몇 주 동안의 데이터를 저장합니다. 핫 노드에 비해 성능 좋은 디스크나 큰 메모리는 필요 없지만 많은 데이터를 저장하기 위해 대용량 디스크를 사용합니다. 회복탄력성을 위해 하나 이상의 레플리카를 사용하는 것을 권장합니다.
콜드 노드
node.roles = [ data_cold ] 콜드 노드에는 프리즈(Freeze) 모드의 인덱스들을 저장하게 되는데, 프리즈 모드의 인덱스는 평상시에는 띄워놓지 않으므로 인덱스를 유지하기 위한 메모리 공간이 필요하지는 않으나, 검색 요청이 올 때 스냅샷 저장소에 저장된 인덱스 파일을 오픈하기 때문에 검색 시간이 많이 소요됩니다. 하지만 완전히 마운트 된 인덱스(Full mounted indicies) 상태라면 안정성을 위해 레플리카 구축이 필요 없으며 데이터 저장을 위한 로컬 저장소를 아낄 수 있습니다. 완전히 마운트 된 인덱스는 읽기 전용입니다.
주로 검색을 수행하지는 않지만 데이터 보존 기간이 정책상 보관해야만 하는 데이터들이 이에 해당됩니다. 하드웨어는 시스템 내에서 지원하는 최소한의 사양으로 구성하되 디스크의 용량만 필요한 만큼 갖추면 되고, 가용성을 위한 시스템 구성은 굳이 필요하지 않습니다.
프로즌 노드
node.roles = [ data_frozen ] 콜드 노드에 존재하는 데이터 중 더 이상 조회되지 않거나, 거의 조회되지 않는 데이터의 경우 프로즌 노드로 옮겨서 데이터를 더 오래 관리할 수 있게 됩니다.
프로즌 노드에는 스냅샷 저장소가 필요합니다. 부분적으로 마운트 된 인덱스(Partially mounted indices)를 사용해서 스냅샷 저장소에 있는 데이터를 읽고 저장합니다. 이렇게 하면 로컬 저장소 운영 비용이 절감됩니다. Elasticsearch는 가끔은 스냅샷 저장소에서 고정된 데이터를 불러와야 하는데, 이는 콜드 티어보다 느립니다.
컨텐츠 노드
node.roles = [ data_content ]컨텐츠 노드에는 주로 비 시계열 데이터가 저장됩니다. 예를 들면, 제품 설명서나 문서 저장 용도로 사용됩니다. 시계열 데이터와 달리 컨텐츠 데이터는 시간이 지나도 비교적 변동성이 낮기 때문에, 핫/웜/콜드 노드처럼 시간이 지남에 따라 다른 특성을 가진 노드로 이동하는 것은 무의미합니다.
컨텐츠 노드에 저장되는 데이터의 특징으로,
- 변동성이 거의 없어야 하며, 오랜 기간 저장되길 기대한다.
- 얼마나 오래 저장되었는지에 관계없이 빠르게 검색할 수 있어야 한다.
컨텐츠 노드의 특징으로,
- 복잡한 검색과 집계를 빠르게 처리할 수 있도록, IO throughput보다 처리 속도가 더 중요합니다.
- 회복탄력성 관점에서 컨텐츠 노드는 하나 이상의 레플리카를 구성하는 것을 권장합니다.
위에서 언급한 "스냅샷 저장소(Snapshot repository)"는 로컬 저장소 or 클라우드 저장소를 기반으로 구성됩니다. 예를 들면, AWS의 솔루션 중 S3를 활용할 수 있습니다.
다양한 데이터 노드를 활용한 클러스터 구성 예시
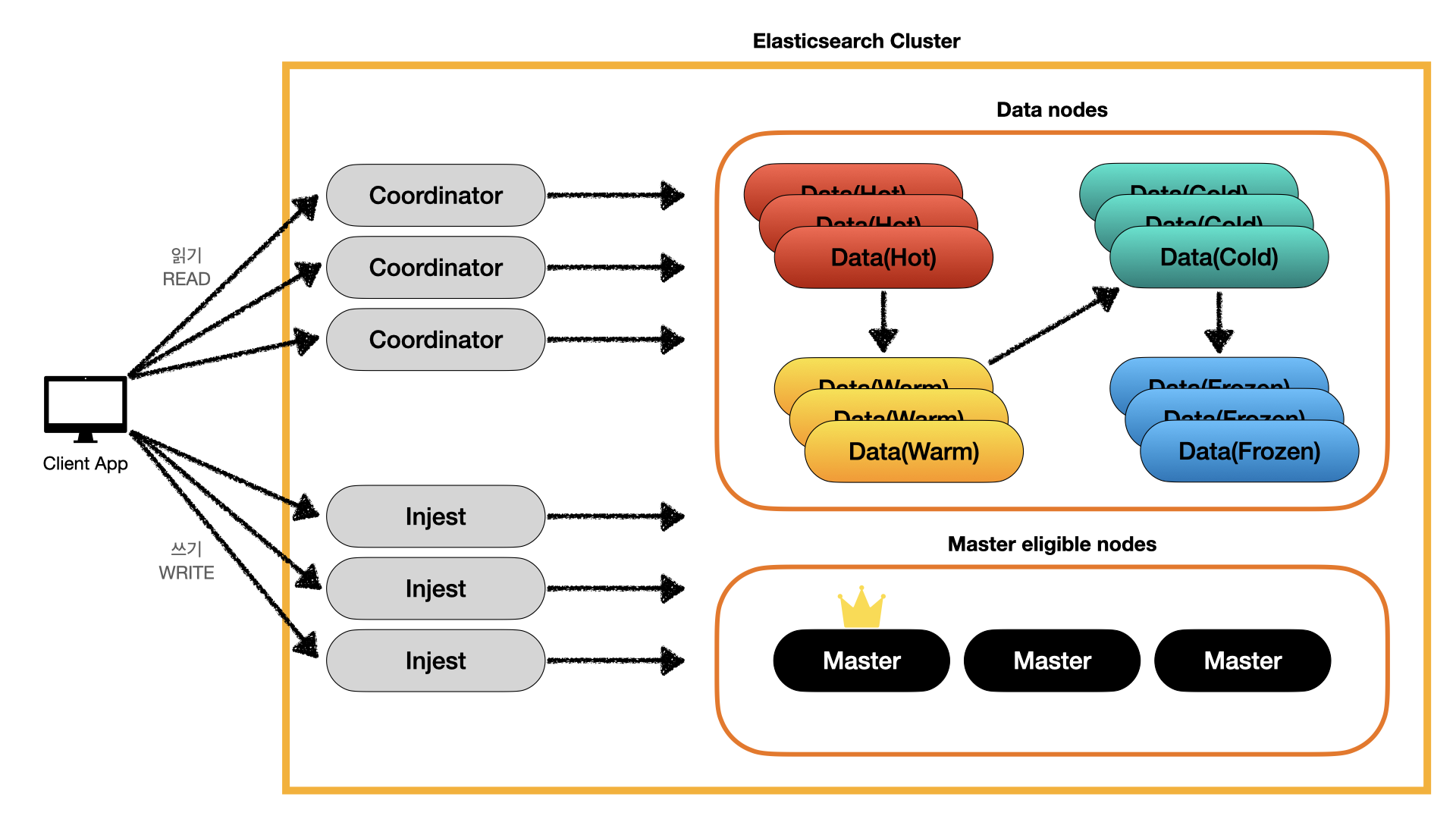
클러스터 구성 예시를 들어봤습니다. 클러스터는 총 21대의 노드로 구성됩니다.
코디네이터 3 + 인제스트 3 + 데이터 12(핫 3 + 웜 3 + 콜드 3 + 프로즌 3) + 마스터 3
위 클러스터 구성은 다음과 같은 특징을 가집니다.
- 읽기 요청/응답은 코디네이터 노드를 통과하며 로드밸런싱, 캐싱, 결과 집계 등의 기능을 사용합니다.
- 쓰기 요청/응답은 인제스트 노드를 통과하며 데이터가 수집, 가공되는 기능을 사용합니다.
- 데이터 노드는 4개의 티어로 구분되며, 데이터 성질에 따라 핫, 웜, 콜드, 프로즌 으로 구분됩니다.
- 마스터 후보 노드는 3개 존재합니다. 마스터 노드의 고유한 역할에만 집중합니다.
다양한 데이터 노드를 구성하는 방법
핫/웜/콜드 노드를 구성할 때 샤드 할당 필터링(Shard allocation filtering) 기술이나 데이터 티어링(Data tiering) 기술을 사용합니다. 샤드 할당 필터링은 샤드를 조건에 따라 특정 노드에 저장하는 방법이고, 데이터 티어링은 7.10 버전에 추가된 기능으로 하드웨어가 동일한 노드를 묶는 방법입니다.
샤드 배치는 매우 중요한 일이기 때문에 단순히 하드웨어 성능으로 묶는 것보단, 세밀하게 배치하는 것이 중요합니다. 따라서 간단한 데이터 티어링보다는 샤드 할당 필터링 방식에 대해 조금 더 자세히 알아보겠습니다.
데이터 티어링에 대해 더 자세히 알고 싶다면 아래 링크를 참고해 주세요.
https://www.elastic.co/guide/en/elasticsearch/reference/8.10/data-tiers.html
그 외 다양한 샤드 할당 방법에 대해 알고 싶다면 아래 링크를 참고해 주세요.
https://www.elastic.co/guide/en/elasticsearch/reference/8.10/index-modules-allocation.html
샤드 할당 필터링
샤드를 필터링하는 방법은 다음과 같습니다.
- 특정 노드에 속성(hot/warm/...)을 추가합니다.
- 인덱스를 특정 노드의 속성에 맞게 저장합니다.
아래에서 상황에 맞게 샤드 필터링을 설정하는 방법을 알아봅시다.
노드에 속성을 추가하려면?
우선 핫/웜 노드로 사용 예정인 노드에 가서 속성을 추가해줘야 합니다. 속성을 추가하고 싶은 노드의 elasticsearch.yml 파일에 아래 속성을 추가/변경해 주면 됩니다. 참고로 node_tag라는 이름은 임의로 지은 것이니 원하는 이름을 사용하면 됩니다.
node.attr.node_tag: hot
인덱스에 속성을 추가하려면?
인덱스에 속성 태그를 추가해 주면 인덱스의 모든 도큐먼트, 즉 샤드가 특정 노드로 인덱싱 됩니다. 아래와 같이 PUT 요청을 보내면 test_today 인덱스에 hot 태그를 설정할 수 있습니다. `index.routing.allocation.require` 는 샤드 필터링 조건을 정의하기 위한 파라미터입니다. 뒤에 붙은 node_tag의 값과 노드에 적용된 node_tag 값을 비교해서 같은 값을 가진 노드로 저장되는 기능을 합니다.
curl -XPUT localhost:9200/test_today/_settings -d '{
"index.routing.allocation.require.node_tag" : "hot"
}'
핫 노드에 저장된 인덱스를 웜 노드로 옮기고 싶다면?
일반적으로 쓰기 작업은 모두 핫 노드에서 진행됩니다. 하지만 기존 핫 노드에 있던 인덱스 중 오래됐거나 사용 빈도가 떨어지는 인덱스는 웜 노드(혹은 콜드)로 옮기는 것이 적절합니다. 아래 예시는 test_yesterday 인덱스를 warm 노드로 옮기는 요청입니다.
curl -XPUT localhost:9200/test_yesterday/_settings -d '{
"index.routing.allocation.require.node_tag" : "warm"
}'
키바나를 통해 인덱스 관리하기
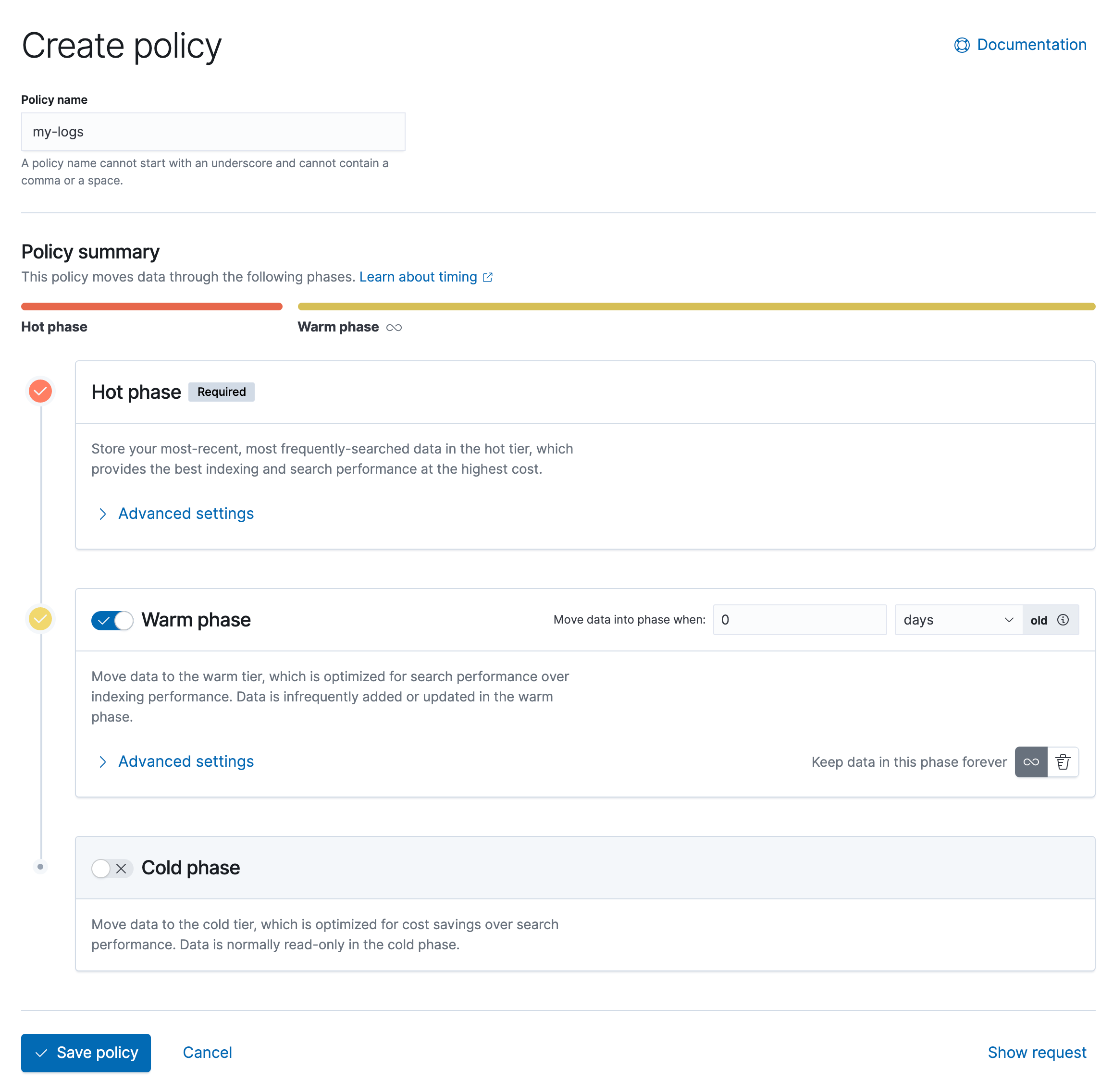
키바나의 메뉴 중 Management > Stack Management > Index Lifecycle Policies에 들어가면 인덱스 생명 주기를 관리할 수 있습니다. 인덱스 별로 Hot/Warm/Colde 중 어떤 phase에서 운영할 것인지 편하게 설정할 수 있습니다.
로컬에서 실행해 봤는데, 저는 라이센스가 없어서 사용할 수 없는 기능인 것 같습니다 ㅠㅠ
맺음말
지난 글에서 다룬 마스터 노드를 선출하는 과정, 이번 글에서 다룬 데이터 접근 빈도에 따른 티어 분리. 이런 내용들은 Elasticsearch 에만 국한되어 활용하는 것이 아닌 것 같습니다. 알아두면 좋은 지식 ~!
지적 질문 환영합니다~