[ELK] Nori(노리) Tokenizer로 형태소 분석하기 /w Docker
안녕하세요. 황진성입니다.
오늘은 한글 형태소 분석기를 사용해서 주어진 텍스트에서 필요한 단어만 뽑아내는 방법에 대해 알아보겠습니다. 또한 나만의 사전을 만들어서 커스텀 분석기를 만드는 것까지 실습해 보겠습니다.
아래에서 진행한 모든 내용은 작성일 기준 Elasticsearch 8.10에서 정상적으로 동작합니다.
노리 형태소 분석기란?
한국어 형태소 분석기 중 많이 사용되는 형태소 분석기인 노리(Nori) 입니다. 노리는 Elasticsearch 엔진과 함께 구동하는 것이 일반적입니다. Lucene 분석 모듈을 사용하기 때문입니다. 노리는 mecab-ko-dic 사전을 통해 한국어 분석을 수행합니다.
(제가 ES와 분리된 형태로 사용하는 방법을 찾아봤는데 못 찾았습니다.. 아시는 분은 제보 부탁드립니다. -_-)
설치하기
저는 지난 글에서 소개했듯, Docker Compose 환경에서 ELK를 사용하고 있습니다.
[💻 개발 이야기/ELK Stack] - [ELK] 초심자를 위한 Elasticsearch, Logstash, Kibana를 Docker로 실행하기
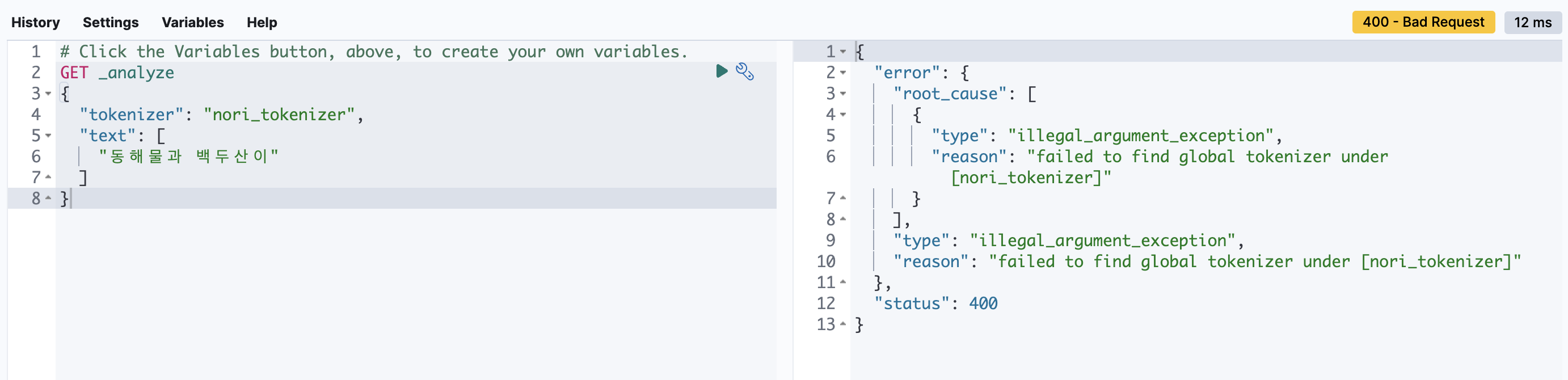
Kibana의 Dev Tools > Console에서 쿼리를 날려봤습니다.
GET _analyze
{
"tokenizer": "nori_tokenizer",
"text": [
"동해물과 백두산이"
]
}
로컬 환경에 설치하기
로컬 환경에서 Elasticsearch를 운영하고 있다면, `bin/elasticsearch-plugin` 을 통해 설치할 수 있습니다. 곧바로 아래 명령어를 통해 설치해 봅시다.
./bin/elasticsearch-plugin install analysis-nori
설치가 끝났다면 Elasticsearch 프로세스를 죽인 뒤 다시 실행해 줍니다.
컨테이너 환경에 설치하기
저는 Docker 컨테이너 기반으로 ELK를 실행하고 있습니다. 실행하고자 하는 Elasticsearch 이미지를 빌드하는 Dockerfile을 찾아갑니다. 아래와 같이 `RUN elasticsearch-plugin install analysis-nori` 을 한 줄 추가해 줍니다.
# Dockerfile
ARG ELASTIC_VERSION
FROM docker.elastic.co/elasticsearch/elasticsearch:${ELASTIC_VERSION}
RUN elasticsearch-plugin install analysis-nori한 줄 추가했다면 꼭 도커 이미지를 re-build 해줘야 합니다. (요거 까먹고 계속 안 돼서 4시간 날렸습니다🤯)
🧐 Pro tips
근데 여기서 궁금한 점이 생겼습니다. 로컬에 실행할 때는 설치 후 프로세스를 죽였다 다시 켜야 잘 동작했습니다. 하지만 Dockerfile에 RUN 으로 명령을 추가했다면, 분명 Elasticsearch 컨테이너를 띄우고 install 명령을 실행할 텐데 재기동 없이 잘 동작한다는 점입니다. analysis-nori 를 컨테이너 외부 파일 시스템에 마운트 해서 쓰는 게 아니라 컨테이너 내부에서 설치하는 건데 어떻게 이게 가능한 건지 궁금해졌습니다.
이건 Dockerfile 빌드 과정에 비밀이 숨어 있었습니다. Dockerfile로 이미지를 빌드할 때 수행되는 각 명령어는 이미지에 새로운 레이어를 생성합니다.
Dockerfile에서 RUN 명령어를 실행하면 다음 순서로 동작합니다.
- 현재까지 실행된 이미지 레이어에서 임시 컨테이너를 생성한다.
- 임시 컨테이너에서 해당 명령어를 실행한다. (위 경우에는 Install 명령)
- 변경 사항을 커밋하고 새로운 레이어를 생성한다.
여기서 RUN 명령을 수행하며 생성되거나 수정되는 모든 파일과 디렉터리 또한 레이어 커밋 사항에 포함됩니다. 즉, 임시 컨테이너를 통해 설치 명령을 수행하고, 변경된 파일 시스템을 가지고 있는 상태에서 컨테이너를 띄우기 때문에 별도의 재기동 없이 노리 분석기를 사용할 수 있었습니다.
사용해 보자
우선 테스트용 인덱스를 하나 만들었습니다. (설정 정보 외 데이터는 인덱스에 저장하지 않습니다)
PUT /products
"산뜻한 크림치즈"를 분석해 봅시다.
GET /products/_analyze
{
"tokenizer": "nori_tokenizer",
"text": [
"산뜻한 크림치즈"
]
}{
"tokens": [
{
"token": "산뜻",
"start_offset": 0,
"end_offset": 2,
"type": "word",
"position": 0
},
{
"token": "하",
"start_offset": 2,
"end_offset": 3,
"type": "word",
"position": 1
},
{
"token": "ᆫ",
"start_offset": 2,
"end_offset": 3,
"type": "word",
"position": 2
},
{
"token": "크림",
"start_offset": 4,
"end_offset": 6,
"type": "word",
"position": 3
},
{
"token": "치즈",
"start_offset": 6,
"end_offset": 8,
"type": "word",
"position": 4
}
]
}제가 뽑길 원했던 단어는 "크림치즈" 였는데, 크림과 치즈 또한 명사로 분리하고 있습니다. "크림치즈"는 묶어서 다루도록 설정해 보겠습니다.
Explain 결과는 펼쳐서 확인하실 수 있습니다.
GET /products/_analyze
{
"tokenizer": "nori_tokenizer",
"explain": true,
"text": [
"산뜻한 크림치즈"
]
}{
"detail": {
"custom_analyzer": true,
"charfilters": [],
"tokenizer": {
"name": "nori_tokenizer",
"tokens": [
{
"token": "산뜻",
"start_offset": 0,
"end_offset": 2,
"type": "word",
"position": 0,
"bytes": "[ec 82 b0 eb 9c bb]",
"leftPOS": "XR(Root)",
"morphemes": null,
"posType": "MORPHEME",
"positionLength": 1,
"reading": null,
"rightPOS": "XR(Root)",
"termFrequency": 1
},
{
"token": "하",
"start_offset": 2,
"end_offset": 3,
"type": "word",
"position": 1,
"bytes": "[ed 95 98]",
"leftPOS": "XSA(Adjective Suffix)",
"morphemes": null,
"posType": "MORPHEME",
"positionLength": 1,
"reading": null,
"rightPOS": "XSA(Adjective Suffix)",
"termFrequency": 1
},
{
"token": "ᆫ",
"start_offset": 2,
"end_offset": 3,
"type": "word",
"position": 2,
"bytes": "[e1 86 ab]",
"leftPOS": "E(Verbal endings)",
"morphemes": null,
"posType": "MORPHEME",
"positionLength": 1,
"reading": null,
"rightPOS": "E(Verbal endings)",
"termFrequency": 1
},
{
"token": "크림",
"start_offset": 4,
"end_offset": 6,
"type": "word",
"position": 3,
"bytes": "[ed 81 ac eb a6 bc]",
"leftPOS": "NNG(General Noun)",
"morphemes": null,
"posType": "MORPHEME",
"positionLength": 1,
"reading": null,
"rightPOS": "NNG(General Noun)",
"termFrequency": 1
},
{
"token": "치즈",
"start_offset": 6,
"end_offset": 8,
"type": "word",
"position": 4,
"bytes": "[ec b9 98 ec a6 88]",
"leftPOS": "NNG(General Noun)",
"morphemes": null,
"posType": "MORPHEME",
"positionLength": 1,
"reading": null,
"rightPOS": "NNG(General Noun)",
"termFrequency": 1
}
]
},
"tokenfilters": []
}
}
나만의 사전 생성하기
어떻게 하면 "크림치즈"를 "크림" + "치즈"가 아니라 "크림치즈"로 활용할 수 있을까요?
글 위쪽에서 언급했듯, 노리 토크나이저는 mecab-ko-dic을 기반으로 형태소 분석을 진행합니다. "크림"과 "치즈" 또한 해당 사전에 의해 잘 분리되는 것이 맞지만, 제 목적에는 맞지 않습니다. 따라서 사용자 목적에 맞는 사전을 txt 형태로 추가하고, 그 txt 파일 안에 있는 단어들은 분리되지 않는 하나의 고유 명사로 등록해 줄 수 있습니다.
우선, 나만의 사전 이름을 "products_ko.txt" 로 짓고, config 디렉터리에 생성해 줍니다. 그리고 "크림치즈"라는 단어를 추가해 줍니다.
$ touch config/products_ko.txt
$ echo "크림치즈" >> config/products_ko.txt$ cat config/products_ko.txt
크림치즈
Docker 컨테이너 환경을 사용하고 있다면 볼륨 마운트도 필요합니다. 저는 docker-compose.yml 파일을 수정해 줬습니다.
elasticsearch:
volumes:
- ./elasticsearch/config/products_ko.txt:/usr/share/elasticsearch/config/products_ko.txt:ro,Z
커스텀 토크나이저 생성하기
이제 나만의 사전이 적용된 커스텀 토크나이저를 추가해 보겠습니다. 다만, 토크나이저 및 분석기 설정은 인덱스를 닫은 상태에서 진행해야 합니다. 닫고 설정을 진행하며, 끝났다면 잊지 말고 다시 열어줍니다.
POST /products/_close
PUT /products/_settings
{
"analysis": {
"tokenizer": {
"products_tokenizer": {
"type": "nori_tokenizer",
"decompound_mode": "mixed",
"user_dictionary": "products_ko.txt"
}
},
"analyzer": {
"custom_nori_products": {
"type": "custom",
"tokenizer": "products_tokenizer"
}
}
}
}
POST /products/_open
- 토크나이저는 nori_tokenizer 기반이며, 이름은 products_tokenizer로 설정했습니다.
- 분석기는 커스텀 타입이며, 방금 생성한 products_tokenizer 를 토크나이저로 사용합니다.
- decompound_mode를 mixed 로 설정했습니다.
이제 "크림치즈"가 하나의 단어로 잘 나오는지 확인해 봅시다. 토크나이저는 방금 생성한 토크나이저를 넣어줘야 합니다.
GET /products/_analyze
{
"tokenizer": "products_tokenizer",
"text": [
"산뜻한 크림치즈"
]
}{
"tokens": [
{
"token": "산뜻",
"start_offset": 0,
"end_offset": 2,
"type": "word",
"position": 0
},
{
"token": "한",
"start_offset": 2,
"end_offset": 3,
"type": "word",
"position": 1,
"positionLength": 2
},
{
"token": "하",
"start_offset": 2,
"end_offset": 3,
"type": "word",
"position": 1
},
{
"token": "ᆫ",
"start_offset": 2,
"end_offset": 3,
"type": "word",
"position": 2
},
{
"token": "크림치즈",
"start_offset": 4,
"end_offset": 8,
"type": "word",
"position": 3
}
]
}마지막에 "크림치즈"가 하나의 단어로 나오는 것을 확인하실 수 있습니다!
Explain 결과는 펼쳐서 확인하실 수 있습니다.
GET /products/_analyze
{
"tokenizer": "products_tokenizer",
"explain": true,
"text": [
"산뜻한 크림치즈"
]
}{
"detail": {
"custom_analyzer": true,
"charfilters": [],
"tokenizer": {
"name": "products_tokenizer",
"tokens": [
{
"token": "산뜻",
"start_offset": 0,
"end_offset": 2,
"type": "word",
"position": 0,
"bytes": "[ec 82 b0 eb 9c bb]",
"leftPOS": "XR(Root)",
"morphemes": null,
"posType": "MORPHEME",
"positionLength": 1,
"reading": null,
"rightPOS": "XR(Root)",
"termFrequency": 1
},
{
"token": "한",
"start_offset": 2,
"end_offset": 3,
"type": "word",
"position": 1,
"positionLength": 2,
"bytes": "[ed 95 9c]",
"leftPOS": "XSA(Adjective Suffix)",
"morphemes": "하/XSA(Adjective Suffix)+ᆫ/E(Verbal endings)",
"posType": "INFLECT",
"reading": null,
"rightPOS": "E(Verbal endings)",
"termFrequency": 1
},
{
"token": "하",
"start_offset": 2,
"end_offset": 3,
"type": "word",
"position": 1,
"bytes": "[ed 95 98]",
"leftPOS": "XSA(Adjective Suffix)",
"morphemes": null,
"posType": "MORPHEME",
"positionLength": 1,
"reading": null,
"rightPOS": "XSA(Adjective Suffix)",
"termFrequency": 1
},
{
"token": "ᆫ",
"start_offset": 2,
"end_offset": 3,
"type": "word",
"position": 2,
"bytes": "[e1 86 ab]",
"leftPOS": "E(Verbal endings)",
"morphemes": null,
"posType": "MORPHEME",
"positionLength": 1,
"reading": null,
"rightPOS": "E(Verbal endings)",
"termFrequency": 1
},
{
"token": "크림치즈",
"start_offset": 4,
"end_offset": 8,
"type": "word",
"position": 3,
"bytes": "[ed 81 ac eb a6 bc ec b9 98 ec a6 88]",
"leftPOS": "NNG(General Noun)",
"morphemes": null,
"posType": "MORPHEME",
"positionLength": 1,
"reading": null,
"rightPOS": "NNG(General Noun)",
"termFrequency": 1
}
]
},
"tokenfilters": []
}
}
맺음말
제가 형태소 분석기를 통해 멋진 기능을 만들고자 하는 계획을 가지고 있었는데, 생각보다 공부해야 할 양이 많아서 주춤하게 되네요. 노리 형태소 분석기 관련해서 핸즈온 실습은 요 정도로 마치고, 앞으로는 다양한 활용기로 찾아오도록 하겠습니다.
사실 이 글을 쓰며 테스트를 많이 해봤는데 노리 형태소 분석기가 생각보다 성능이 좋아서 배워두면 앞으로 어디든 써먹을 곳이 많을 것 같습니다. 긴 글 읽어주셔서 감사합니다!!
References
- https://www.elastic.co/guide/en/elasticsearch/plugins/current/analysis-nori.html
- https://www.elastic.co/guide/en/elasticsearch/plugins/current/analysis-nori-tokenizer.html